My primary research interest at the moment is the visualization of language and linguistic information, known as LInfoVis or LangVis. My goal is to help language professionals (linguists of all sorts, humanists, translators, terminologists, etc.) understand their data more easily. The human visual system has highly developed pattern recognition capabilities — for example, the colored text above probably drew your attention. We can take advantage of those cognitive capabilities to help language professionals find patterns in their data.

Word Formation Latin Project: For the Word Formation Latin project — freely available at wfl.marginalia.it — I collaborated with Classics scholars and computational linguists to make their unique database of Latin word formation accessible to a broad audience, from scholars, to teachers, to student, to the general public. I designed and implemented the site interactions based on my colleagues' workflows; implemented an innovative analysis of the database to provide a menu driven query system; and designed and implemented interactive visualizations, which incorporate the results of simple graph analysis of the database.

General visualization tools: As part of the practical aspect of visualization, I have created a variety of freely available visualization tools.
Vistola project: This project is about the visualization and analysis of person-oriented correspondence. It reflects my interest in both the theoretical aspects of visualization (especially visualizations as models of data) as well as practical aspects (e.g. building flexible reusuable visualization tools for linguistic data). New! Visualizing Letters Demo Videos
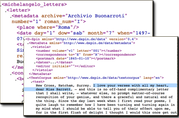
In connection with the Vistola project on correspondence, I, with help from students, have created a few corpora of letters or email messages, most annotated with lemmas and parts of speech in addition to the metadata associated with the letters. A few other annotated, non-correspondence texts can also be found in the BAAL workshop materials.
I have also made a selection of my invited presentations available for viewing online. The talks were not intended as knowledge repositories, and there is therefore relatively little explanatory text. However, the online versions will give you an introduction to some of my research topics and areas of interest.